
1. 📘 Background: Why We Needed a Cron Service
we had a growing set of scheduled tasks—ranging from Kafka consumers to SQS listeners and custom time-based jobs. These were originally scattered across different services and tightly coupled to their respective modules. As the complexity grew, it became difficult to:
- Monitor failures
- Handle retries
- Scale task execution independently
We decided to build a dedicated cron-service that could centrally manage all job scheduling using Spring Boot, Quartz, and MySQL.
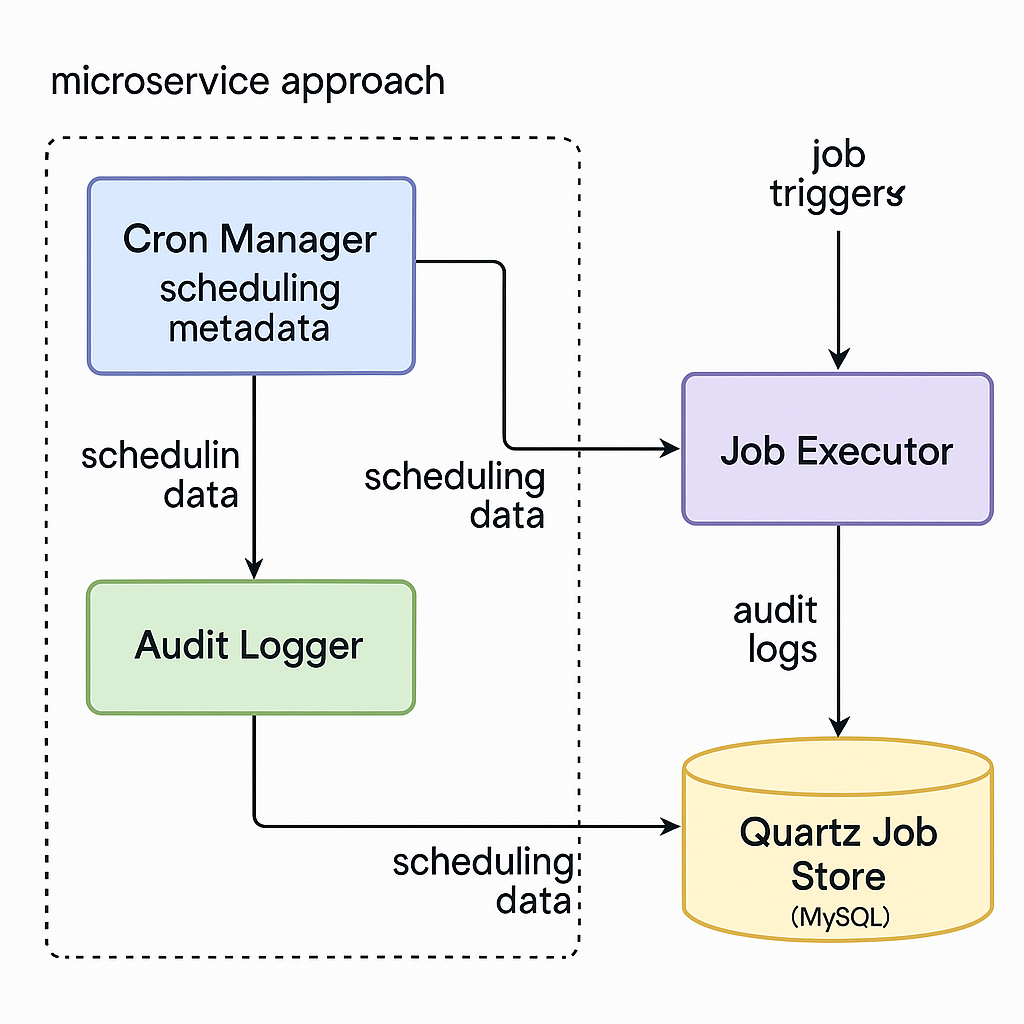
2. 🧱 Architecture Overview
The system follows a microservice approach with the following key components:
- Scheduler Manager: Handles registration and metadata of jobs.
- Quartz Engine: Executes jobs using Quartz library.
- Job Registry: Set of Spring-managed job beans.
- Database (MySQL): Stores Quartz job data and job audit logs.
[System Diagram]
3. ⚙️ Quartz + Spring Boot Integration
Quartz offers a mature and flexible scheduling library. We wrapped Quartz jobs using a custom annotation:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface QuartzScheduled {
String name();
String cron();
boolean enabled() default true;
}We use Spring to scan and register annotated jobs at runtime. Jobs can also be stored in the DB to allow dynamic changes.
4. 🗒️ Multi-DB Support (Master, Read, Shard Reads)
Our service supports:
- Master DB: Used for all Quartz metadata updates
- Read Replicas: Used for read-heavy schedulers
- Shard Reads: Some jobs are tied to specific customer shards
We used Spring’s AbstractRoutingDataSource to dynamically route based on job context:
public class DataSourceRouter extends AbstractRoutingDataSource {
protected Object determineCurrentLookupKey() {
return DbContextHolder.getDbKey();
}
}5. 📡 Kafka & SQS Integration (Optional)
Some of our jobs are responsible for consuming events from Kafka topics or SQS queues. Instead of running consumers in separate services, we defined Quartz jobs that trigger these handlers periodically and track offsets or state.
.![]()
If you’re new to Kafka or want a deeper dive into its architecture, I highly recommend this great read:
👉 Apache Kafka: The Backbone of Modern Data Streaming
This integration helps us simplify retry, monitoring, and control job execution windows.
6. 🧪 Failure Handling, Retry, and Monitoring
To ensure reliability:
- Retry Strategy: Jobs can be configured to auto-retry on failure with exponential backoff.
- Dead Letter Tracking: Failed jobs beyond retry limit are pushed to a DLQ table.
- Monitoring: Prometheus + Grafana dashboard for job metrics.
Moreover, failed jobs can trigger alerts through Slack or email, improving our incident response.
7. 🧩 Extensibility
Each team can add a new job by simply creating a Spring bean with @QuartzScheduled and implementing Job interface. Example:
@Component
@QuartzScheduled(name = "CustomerCleanup", cron = "0 0 1 * * ?")
public class CustomerCleanupJob implements Job {
public void execute(JobExecutionContext context) {
// logic
}
}Thus, developers can focus on writing logic instead of boilerplate.
8. 💡 Challenges & Learnings
While building the system, we encountered several challenges:
- Quartz Locking: Avoiding DB locks during heavy job bursts.
- Node Coordination: Only one instance executes a clustered job.
- Dynamic Cron Updates: Updating schedule without restarts.
Despite these, we were able to build a robust system that performs reliably in production.
9. 🚀 What’s Next?
Looking ahead, we plan to add:
- Job Console UI: Web interface to view, trigger, or disable jobs.
- Audit Log Viewer
- Webhook Integration: Schedule jobs from external services
By continuing to evolve this system, we aim to empower teams with observability, flexibility, and control over scheduled workflows.
Stay tuned for a future post on how we built the internal Cron Console UI to empower product and support teams!
For more details checkout Spring Quartz Official Blog